Predicting Citation Impact from Peer Review Data
PeerRead-based data analysis and machine learning project for citation impact prediction.
Predicting Citation Impact from Peer Review Data
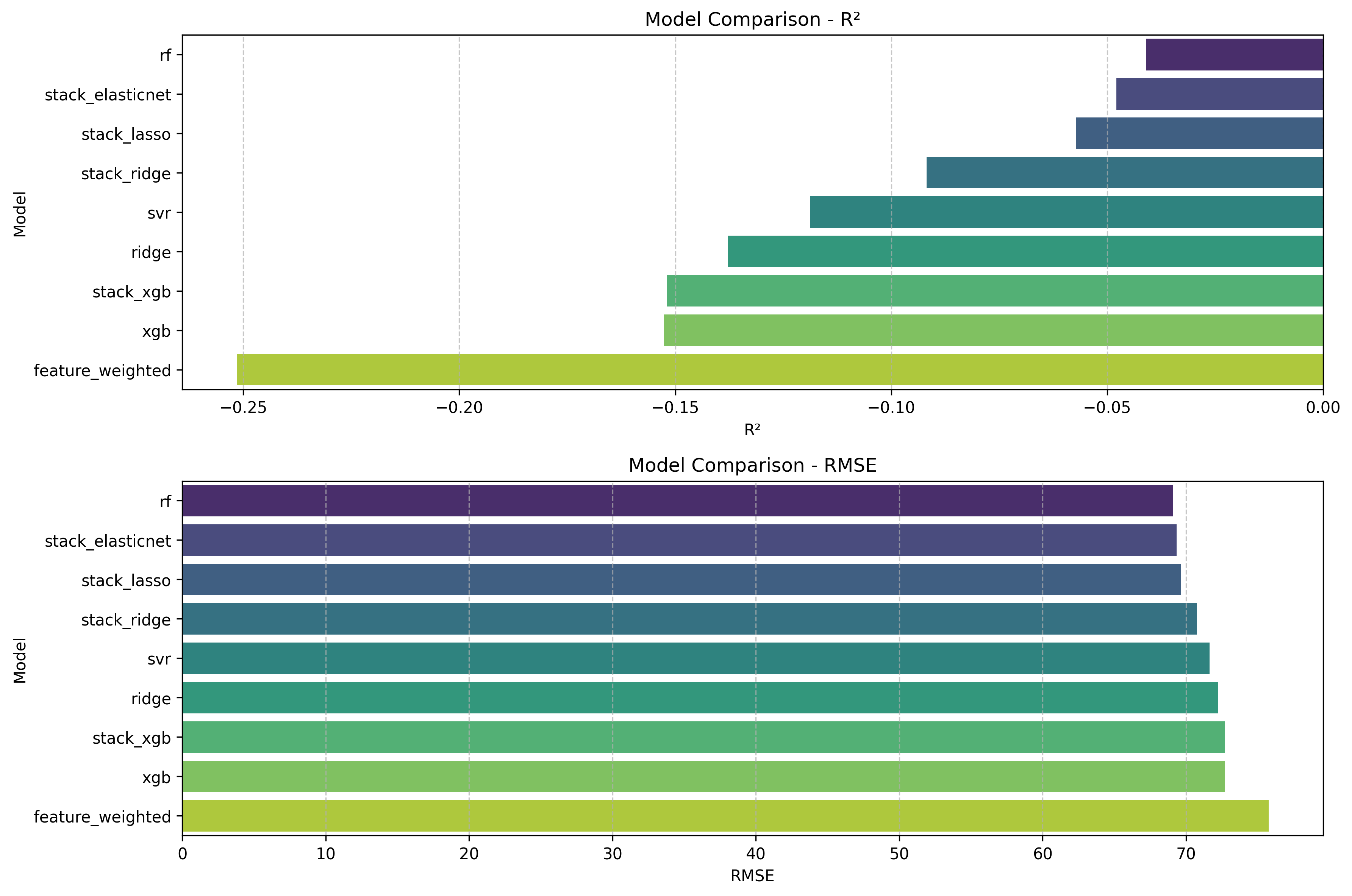
This project explored whether peer review scores and paper metadata can predict future citation impact. It used PeerRead data from ACL 2017 and CoNLL 2016 and treated citation count prediction as a data analysis and machine learning problem.
What It Does
- Cleans and merges peer review, paper metadata, acceptance, and citation-count data.
- Uses PCA, clustering, correlation analysis, and recommendation-level analysis to study review-score structure.
- Compares models including SVR, XGBoost, Random Forest, neural networks, Gaussian processes, and stacked ensembles.
- Discusses selection bias, citation bias, and risks of using predictive models in editorial decision-making.
Key Takeaway
Peer review metrics contain limited signal for long-term citation prediction. Tree-based and non-linear methods can extract some structure, but the results emphasize the limits of standardized review scores as a proxy for future scientific impact.
Tech Stack
Python, pandas, scikit-learn, XGBoost, Matplotlib, Seaborn, Jupyter Notebook.